
Clustered Web Applications - Mysql and File replication
Published 2020-03-05 00:00:00
In mid-2018, one of our clients asked if we could improve the reliability of their web applications. The system was developed by us and was hosted on a single server in Hong Kong. Over the last 5 years or so, the server had been sporadically unavailable due to various reasons
- DDOS attack on the Hosting provider's network
- Hardware failure - both on the hosting machine and the provider's network hardware.
- Disk capacity issues
While most of these had been dealt with reasonably promptly, the service provided by our client to their customers had been down for periods up to a day. So we started the investigation into the solution to make this redundant and considerably more reliable.
Since this was not a financial institution, with endless money to throw at the problem, Amazon, Azure etc. were considered to pricey, and even if they did provide a more reliable solution, there was still a chance that it could still be susceptible to network or DDOS attacks. So the approach we took was to build a cluster of reasonably priced servers (both physical and virtual) hosted at multiple hosting providers.
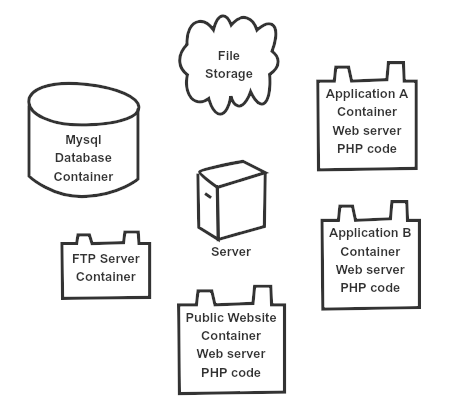
This represented the starting point, we had already separated the Application and Mysql server into individual containers. Which made backups and restoration trivial, along with theoretically making the cluster implementation somewhat simpler
To implement a full clustering solution, not a redundancy solution, we needed to solve a few issues
- Mysql Clustering
- File system Clustering
- Load Balancing
- Private Networking between the various components.
The simplest of these was the Load balancing, we had already been using Cloudflare to provide free SSL (we tend to use letsencrypt on solutions these days, but Cloudflare has proved reasonably resilient. although it does still result in a single point of failure from our perspective)
The other two however proved to be more challenging than we expected.
Mysql Clustering
Anyone who has used MySQL, normally at some point set's up a master/slave backup system. It's pretty reliable, however, when it comes to switching from the master/slave, we concluded that the effort involved, especially considering the size of our database would be problematic. So we started testing out the Mysql Clustering technologies (note we tended to stick to classic MySQL technologies, rather than trying out any of the forks/offshoots).
After our initial analysis, we settled on NDB clustering, the setup of which proved more than a little problematic. In part due to the database restrictions that the storage engine enforced, but eventually having overcome the initial issues with this, by modifying our schemas slightly, we discovered that in our usage scenario, that NDB performance was significantly slower than that of a standalone InnoDB server. To the point where the application became un-usable. This may have been due to various factors, memory limitations, one of the machines using a physical rather than SSD drive. But after many hours of research and testing, we concluded that it was not a viable solution.
After throwing all that research in the bin, the next alternative was an InnoDB cluster. Again this involved quite a learning curve as management of the cluster is done via mysqlsh, which due to the nature of the internet has a wealth of out of date contradicting information all over the internet. Along with rather limited precise information on working configurations. Eventually, we managed to solve both the multitude of configuration settings (enough memory allocated to migrate) and minor schema modifications to enable replication to work. Resulting in the first part of the puzzle being solved.
The final solution for the mysql server involved hosting on 1 physical machine, one virtual machine in Hong Kong and a Linode VPS in Singapore. This has generally met the initial goals of more stability, however, we do have a long term plan to move more to Linode, and remove the Hong Kong physical hardware, as this seems to be our most frequent point of failure. Saying that the machine and network have failed multiple times, but the services have remained up throughout.
In addition to the servers, we also added mysqlrouter to the mix, in the initial design it's running on the same container as the mysql server. in hindsight, it would have been better to have a separate container for this, and the next phase the mysql servers will be hosted on seperate VPS's, and the mysqlrouter container will be running on the application server VPS's.
File Replication
We did some quite extensive testing of clustered file systems, including getting the application up and running on gluster. This again however proved to be a performance issue, and we found that gluster killed both CPU and memory usage.
Eventually, we settled on a multi-pronged approach, the first being unison for two way synchronization. The second being splitting the file system into 'active areas' and archive areas. Our applications generally create files in directories based on YYYY/mm/dd - so a simple script was written to move directories older than a few days from the 'hot' storage area which was replicated using unison (based on inotify watches) and a 'cold' area, that was kept in sync daily using rsync. Softlinks were then created the hot file areas to point to the correct place in the cold storage.
This meant we could handle quite a bit of file activity as one of the applications is constantly creating files, and have those files available on multiple servers. For the next phase of development, we will be running unison in multiple containers for each pair of replication targets. And also considering NFS servers over TCP rather than replication for our main two front end servers.
Private Networking
One of the early issues before we set this all up was to work out how all these different servers would communicate, securely with each other. Normally for private networking, we had used OpenVPN. This is a client-server spoke system, however for a reliable network we would not want to have a single point of failure, and writing scripts to flip between different OpenVPN servers if something failed seemed rather messy.
To solve this we came across tinc, which solved our redundancy problem brilliantly. Tinc is a mesh VPN, which, in theory, can route around broken connections, so with servers A,B,C - if the line is down between C&A then it will route via B. It, as we found later does not handle a 'poor' (dropped packets) connection between C&A very well. You also have to make sure all the firewalls are correctly configured as if you incorrectly configure access to 'C&B', in that 'C&B' can see A, but A can connect directly to C&B, the network will work, however, will fall apart as soon as C goes down. It's a real, cross the t's and dot the I's network, get it correct otherwise when it fails you will be hunting down the issue for a while.
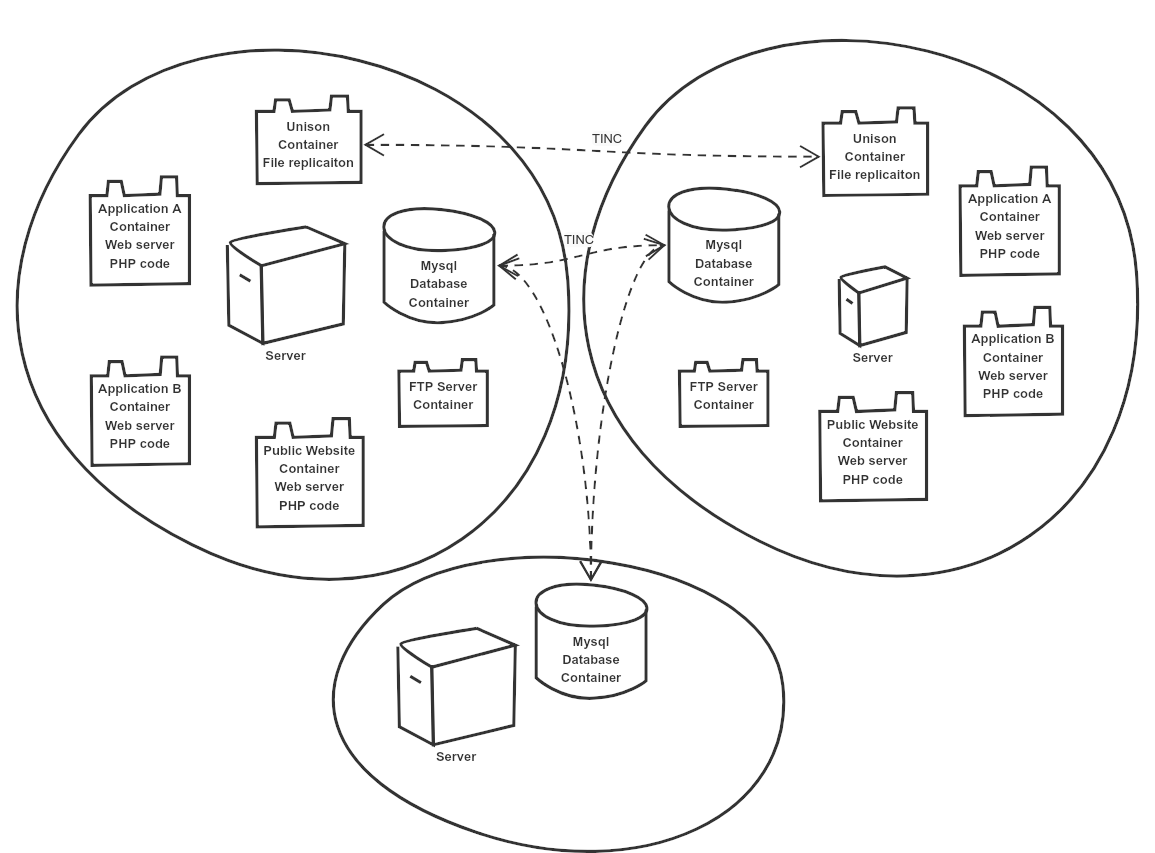
This is a map of the current configuration
Follow us on

 🦋 Bluesky
🦋 Bluesky
OUR BLOG
Bluesky - @roojs.com

 Follow us
Follow us
-
- Some thoughts on the language server and its usefulness in the roobuilder
- Roo Builder for Gtk4 moving forward
- Clustered Web Applications - Mysql and File replication
- GitLive - Branching - Merging
- PDO_DataObject Released
- PDO_DataObject is under way
- Mass email Marketing and anti-spam - some of the how-to..
- Hydra - Recruitment done right
Blog Latest
-
Twitter - @Roojs