Some thoughts on the language server and its usefulness in the roobuilder
Published 2024-04-12 00:00:00
Since adding the
vala language server to
roobuilder I disabled quite a bit of the compiler code that was in the existing code base primarily removing the code copied from
libvala which reduced the long-term maintenance issues
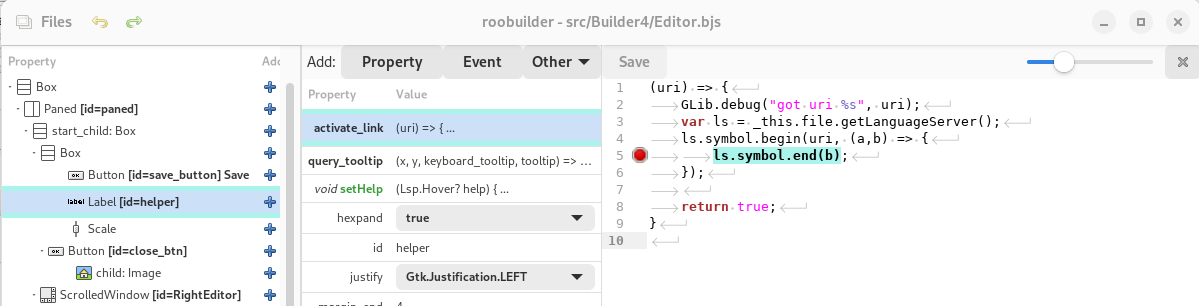
The initial edition of the language server provided the error reporting both for syntax errors that prevented compiles but also warnings and deprecated warnings.
These were nicely integrated into both the editor and the node navigation of the UI builder. This didn't really add a huge change to the existing usability as we already had error reporting like this before however the way that the language server reported errors was far nicer than the original code that we had
Highlighting a warning in the editor
Notably to get the language server working we had to switch to using meson as the build tool. This after working out how to use it proved a major improvement over both autoconf and cmake that I previously been using on other projects. It also made it quite easy to bundle resources like images and data into the compile which I had avoided before. Notably however it did not seem to solve the issue that glib has a settings library which appears to be almost unusable due to the the way it requires things to be done at compile time which would not really be occurring if you installed via packaging.
Completion provider mostly working but a bit slow
The next stage to using the language server was to add the completion engine in. The biggest issues around the completion engine appear to be the requirement that the code is being edited is the same inside the language server as that being edited in the editor.
This means continually passing an up to date version of the text to the language server. The language server then running a compile from there it can work out type of the symbol that is being completed and pass back suggestions. On anything other than a single file or very tiny project this compile can take a few seconds before the completion engine is able to return a list of suggestions.
The end result of this is that the completion pop up frequently appears a minute or so after you finish typing or after you have jumped to another window and it pops up floating in space. It's quite cool for an example but doesn't really seem to have much practical use due to these restrictions. It is also notable that completion suggestions only really work well if you know what method or property you wanted to call or reference. On any kind of large library quite frequently you are not quite sure what that property or method might be so looking up the documentation is frequently the result.
To solve that I started looking at the hover feature of the language server. Initially implementing it as a mouse over hover, this however suffered from the similar problem that the completion engine had, that the round trip back and forth between the server and the editor had enough of a lag that you really have to wait for the hover to appear. So rather than using the hover method for mouse over, I had to go using it to create a context bar at the top of the editor where there was a little white space left over to be used. This seemed like it would actually be a quite useful feature the language server returns quite a good signature of what it is hovering over with things like the type of the symbol eg. the object name or the method and the parameters that might be called.
I'm thinking that this might be useful. I looked at ways in which having got this context menu it was possible to look up the documentation of the object for example all the properties and methods from the language server based on sending it that object type for example the method that was being selected.
hover provider providing a context menu at the top of the code
This is where I started to run into the limitations of the language server. It has some features to search for symbol types but just the simple idea of saying give me all the information you have on this type I couldn't really find any method in the specification to give me that info. It also appears that the number of methods that actually return documentation are quite limited within the specification, so the only ones I initially worked out was hover and completion.
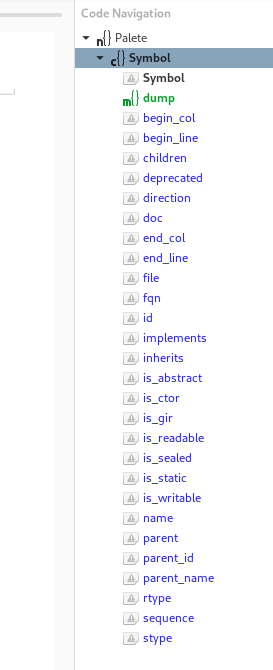
code navigation on the right of the plaintext editor
One thing I did look at was the API to return document symbols, this after a bit of hunting can return a tree of symbols within a document which is extremely handy as a navigational tool to jump to code within a class. That was added as a right hand navigation bar on the plain text editing windows. It always amuses me to see editors with what I think they call mini maps which look like a zoomed out version of a file which seems absolutely pointless as a navigational tool. This tree however shows the methods and properties of the class of the file being edited and I think I made the mouse over show types etc. this however did not really solve the issue as this document symbol feature does not return any help documentation as per the API.
In my usual disorganized plan for the editor and my constant fascination with languages I decided to spend a bit of effort looking into this in more detail. The first step I decided to look at was how the language server was actually extracting the data from both the vapi and gir files. Previously in the original design we fetch quite a bit of the structural data from the vapi to fill in all of the properties for the gtk widgets. This part of the code had a long history as I actually started with the gir files when it was written for the JavaScript seed engine.
That part of code had evolved over time to not actually use much of the gir however it was all structurally named around that and the symbol management which also wrapped the JavaScript user interface builder all shared the same structure.
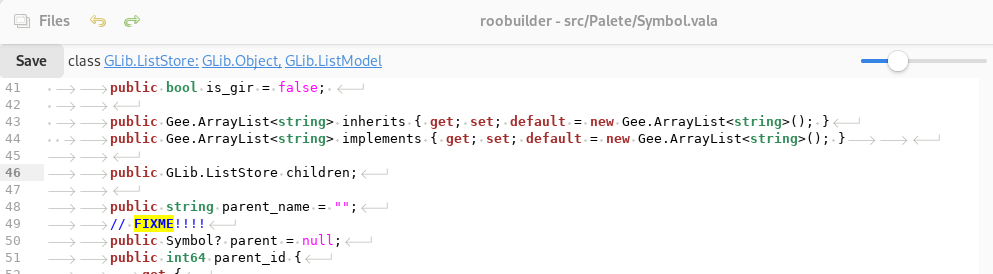
Looking at going forward with this and having the ability to properly query any type of object whether it is part of the library or part of the code base required the ability to use the same way that the language server extracted symbols from the library. The first step was really just to build a proof of concept called from the command line to convert vapi files and the code base into a tree structure. I decided to create a new base class which really just stores these type data and extend this class to handle the various other types like vala or eventually the JavaScript library. And also ended up being wrapped to handle gir files which I will come to later.
Having done this it became pretty clear early on that using this code in line while things are being edited is going to have the same problem that the language server currently has in that the passing really needs to be done in the background and quickly. So it obviously became clear that the whole passing really should be done in a thread. This however leads to the interesting problem that if you are compiling in a separate thread you then need somehow to pass we compile data back to the original thread.
Having worked with SQLite before I had a suspicion this might be a better solution. All of the file structures that we are currently using like gir and vapi, have a tree like structure and the existing data we have storing them in in the previous iteration of the passing engine which was still being used for the properties look like you could really just be mapped into a single table. I also realized that SQLite appears to work with threads although this bit I still have not tested completely. Primarily as we are using memory based databases that I'm guessing will work between the threads.
Phase one was parse the code base with the vapi and store it in the SQL database, initially after a vapi file is being passed there is no need to update the database as that file has not changed in general that part of the engine would not update symbols in the database for files that have not changed. This makes an assumption that the symbol types of files are actively being edited do not affect the symbol database of other files in the project. I still need to understand whether that is really going to be the case but in general I think it is.
Phase two wants to look at the GIR files, these files are still useful as they contain documentation for the object libraries. There is however an issue which needs to be dealt with which is that although generally they map directly to vala there are quite a few instances where the way Vala has wrapped the libraries diverges from the gir files. My initial hope was to use the libvala code in a similar way to the language server to extract the documentation from these files. That however proved to be a bit of a fool's game. Technically within the language server you can actually compile a valid project against these gir files to do bindings in some scenarios. That actual usage however is pretty minimal and to be honest those files are more useful just as a data set for the documentation. And since they're relatively static it would be kind of helpful to just scan the whole lot. Stored in the database and use it when needed rather than specifically scan gir files as needed.
Since the language server uses them in a similar way to the compiler it didn't really like having multiple versions eg. gtk 3 and gtk 4 read in and expect to spit out documentation for both versions hence some really old code that I'd written to handle imports was grabbed to just scan very quickly through these XML files and extract the symbol names and documentation along with the file name version that the code is associated with.
The last part that's been currently done is to wrap this gir extraction into the startup process as a background thread to when you load the builder.
The next steps in theory are to hook in the code compiler to go as a background process when the code is being edited. This probably needs to look a bit better than the current language server interaction, whereby the compilation process needs to be canceled if a new compilation is required, and also the compilation needs to wait until editing has reasonably being completed rather than starting on the first change, which I managed to do with a little trickery on timeouts and asynchronous checks before.
This approach also had an interesting relevance to another significant issue with the editor. Some of the JavaScript user interface files actually contain a huge tree which when edited does cause significance performance issues. Part of these issues are the re-rendering in webkit which can be turned off .. however I think the other issue is that due to the nature of the renderer and the need to store references to the outputted line that maps to each node and property the JavaScript engine doesn't really cache in any sensible way the conversion of the node tree into a file and the data mapping of line to properties. In theory some of this could be speeded up by using more sensible methods to store the line numbers using more relative than absolute numbers. However it does raise the issue that using a similar concept of background threading the rendering of the tree into a string and using the database to store the line numbers means that the background thread generated data could be used by the foreground thread about too many issues. But as usual with the editor design far too many ideas and not enough time.


 🦋 Bluesky
🦋 Bluesky

 Follow us
Follow us